Data
The Numerai dataset is a tabular dataset that describes the global stock market over time.
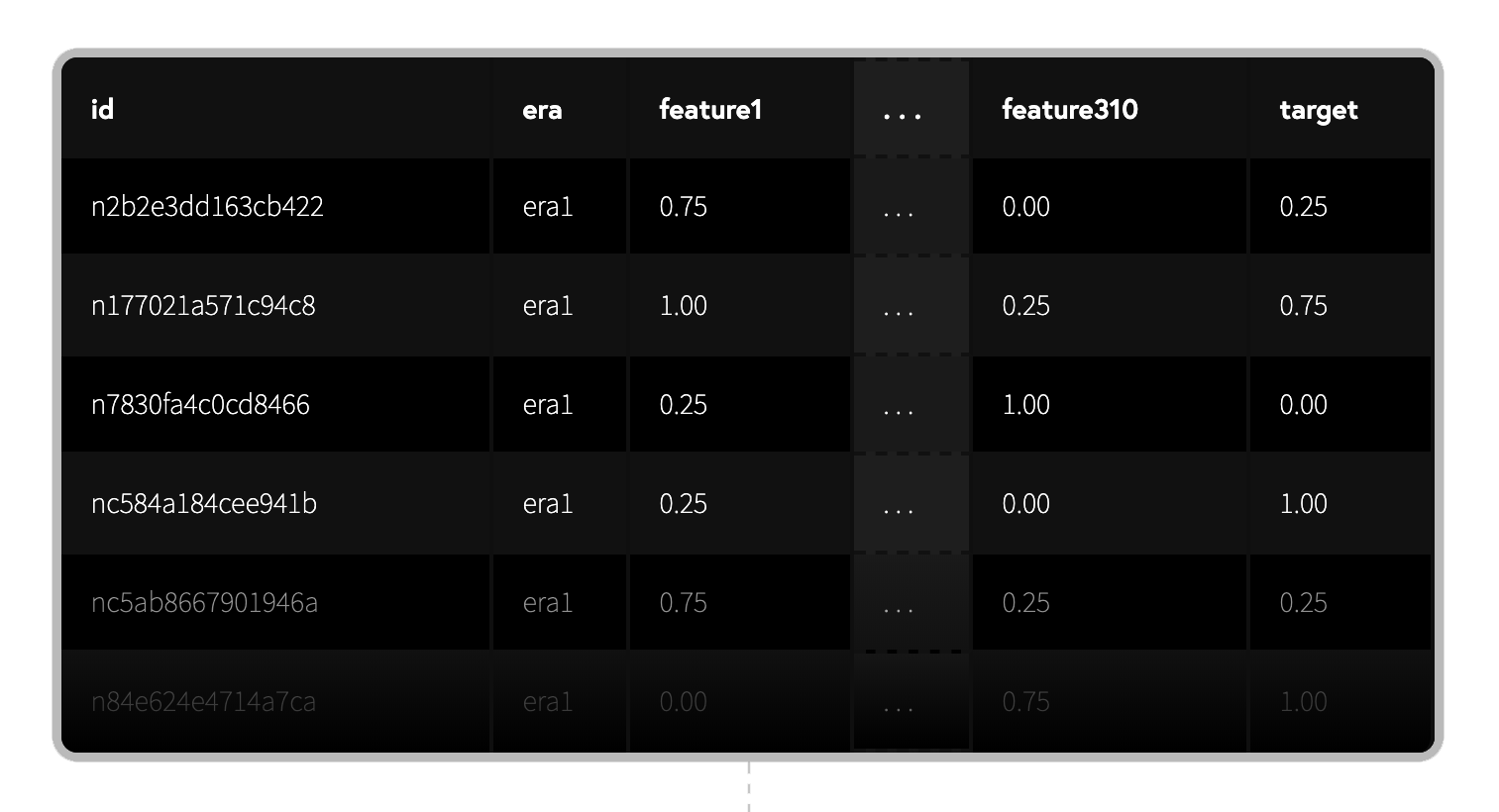
At a high level, each row represents a stock at a specific point in time, where id is the stock id and the era is the date. The features describe the attributes of the stock known on that date. The target is a measure of future returns relative to the date.
IDs
The id is unique per stock per era, this means you cannot track performance of any stock over time. This is pivotal to the encryption of the data and means that you should treat the id as a simple unique identifier for a specific stock at a specific point in time.
Eras
Eras represents different points in time. Specifically, they represent the Friday of each week because that is always the latest market close data to generate predictions over the weekend.
Instead of treating each row as a single data point, you should strongly consider treating each era as a single data point. For this same reason, many of the metrics on Numerai are "per-era", for example mean correlation per-era.
In historical data (train, validation), eras are 1 week apart but the target values can be forward looking by 20 days or 60 days. This means that the target values are "overlapping" so special care must be taken when applying cross validation. See this forum post for more information.
In the live tournament, each new round contains a new era of live features but are only 1 day apart.
Features
There are many features in the dataset, ranging from fundamentals like P/E ratio, to technical signals like RSI, to market data like short interest, to secondary data like analyst ratings, and much more. Feature values for a given era represent attributes as of that point in time.
Each feature has been meticulously designed and engineered by Numerai to be predictive of the target or additive to other features. We have taken extreme care to make sure all features are point-in-time to avoid leakage issues.
While many features can be predictive of the targets on their own, their predictive power is known to be inconsistent across over time. Therefore, we strongly advise against building models that rely too heavily on or are highly correlated to a small number of features as this will likely lead to inconsistent performance. See this forum post for more information.
Note: some features values can be NaN. This is because some feature data is just not available at that point in time, and instead of making up a fake value we are letting you choose how to deal with it yourself.
Targets
The main target of the dataset is specifically engineered to match the strategy of the hedge fund and represent the future performance of a given stock relative to the given era.
Our hedge fund is neutral to many forms of "beta" - we remove our exposure to markets, countries, sectors, or common factors This is because we are in search of "alpha" - returns that you can get from a stock that are not explained by broader trends (e.g. if the whole market goes up or down, we want to make money on specific stocks that over- or under-perform compared to the market). You can can interpret the main target as representing these stock-specific returns.
Apart from the main target we provide many auxiliary targets that are different types of stock-specific returns. Like the main target, these auxiliary targets are also based on stock specific returns but are different in what is "residualized" (eg. neutral to market and country vs neutral to sector and factors) and time horizon (eg. 20 market days into the future vs 60 market days into the future).
Even though our objective is to predict the main target, we have found it helpful to also model these auxiliary targets. Sometimes, a model trained on an auxiliary target can even outperform a model trained on the main target. In other scenarios, we have found that building an ensemble of models trained on different targets can also help with performance.
Note: some auxiliary target values can be NaN but the main target will never be NaN. This is because some target data is just not available at that point in time, and instead of making up a fake value we are letting you choose how to deal with it yourself.
Downloading the Data
The best way to access the Numerai dataset is via the data API. There are many files available for download, but it's best to start by listing them.
Here is an example of how to list our files and versions in Python:
from numerapi import NumerAPI
napi = NumerAPI()
datasets = napi.list_datasets()You can also review the datasets available on our Data Page.
Versions
There are several versions in the data API because Numerai is constantly improving our dataset. In general, if you are building a new model you are encouraged to use the latest version. Each minor version (i.e. v4 vs v4.1 vs v4.2) generally maintains backwards compatibility with each other and makes it easy for you to plug in the latest data to your trained models. Major versions (i.e. v3 vs v4) may have large, breaking changes to the structure and/or contents of the datasets, so it's usually best to re-train your models when major versions are released.
You'll even see versions available for our other tournament, Signals. This is a "bring your own data" tournament that you can read more about here.
Files
The Numerai dataset is made up of many different files in a few different formats. Visit the Numerai Data Page for a full list of files and short descriptions of each file. Here is how to get a small set of training features from the data API in Python:
import pandas as pd
import json
VERSION = "v5.3"
# Download and read the features json file
napi.download_dataset(f"{VERSION}/features.json")
feature_metadata = json.load(open(f"{VERSION}/features.json"))
# use the small feature set to reduce memory usage
small_feature_set = feature_metadata["feature_sets"]["small"]
columns = ["era"]+features+["target"]
# Download and read the training data
napi.download_dataset(f"{VERSION}/train.parquet")
training_data = pd.read_parquet(f"{VERSION}/train.parquet", columns=columns)Formats
The main file format of our data API is Parquet, which works great for large columnar data - we highly encourage that you become familiar with Parquet if you are not already as it is a widely-used format in big data and data science.