OHwA S01E09
From April 30, 2020
From chat: The NMR value staked is different from the Staked Total tab now. Did the increases for pending rounds get dropped from the running total?
Arbitrage recalled that community member Jrai answered this question on Rocket.Chat before asking the audience: “has anyone figured out how to align the reported stake value with what’s actually going on? I haven’t either. I know the team was working on that this week, so I assume that’s what was going on.” He did notice that something was updated in the submissions tab, possibly the hover text over the chart.
Will the Rep Score and Leaderboard matter much after bonuses are gone? Other than bragging rights… Will the Rep Score be replaced with something else?
“I think the intrinsic value of the tournament is your rank,” Arbitrage said, “kind of like Kaggle.”
He hopes the team keeps Reputation, whether or not it’s rewarded, because rank can be a way to document achievement. His students, for example, can include their rank on a resume. “It still is a positive indicator.”
If the weighted average of your reputation is positive, it shows you’ve consistently produced high correlation predictions, and that can be ranked over time. Arbitrage added that, while Rep Score might not matter much beyond bragging rights without the bonus, data scientists should continue to submit predictions in the event Numerai introduces a new payment system based on some kind of rolling performance. Should that happen, it’s in the participant’s best interest to have weekly submission consistency.
“Don’t skip weeks.”
Joakim: I like the leaderboard as well, but it would be nice if we were somehow compensated as well, for being on top of the leaderboard.
Arbitrage: Yeah.
Joakim: But I’ll also say I know that’s easy to game, and I don’t want something that’s easy to game.
Arbitrage: Well that’s the risk, right?
Joakim: Yeah, I don’t know the solution.
Arbitrage: Yeah, that’s the risk. I once suggested doing a once-per-quarter bonus. Maybe every 12 weeks you get paid out in a nonlinear function on reputation? But again — MadMIN is still top of the board, and it’s been there for a long time. To your point, it’s difficult to avoid the gaming. I think we just go with what the team gives us, because throughout the years there have been dozens and dozens of proposals on ways to compensate people without staking, and ultimately it just doesn’t work.
Arbitrage brought up a previous tournament iteration where competitors could earn badges for different achievements, adding that he would support additional leaderboards for different metrics: highest sharpe over 20 weeks, last-minute submissions, longest running model, etc.
Joe asks: Would you blend or optimize your models to maximize Validation 2 correlation or sharpe? If so, what is your strategy to avoid overfitting the Validation 2 data?
Arbitrage answered by explaining that he’s not certain maximizing on the Validation 2 data is the correct path because the data is from a crisis period and, as Richard has mentioned previously, the data isn’t a full year. Because it encompasses the COVID-19 drawdown, it represents a special segment of the Numerai data. “I would be concerned to have a model that performed well on Validation 2 but perhaps didn’t do well on Validation 1,” he said, “I want it to do well on Validation 1 and 2.”
How do you do that? Arbitrage said he doesn’t know, he hasn’t experimented enough with Validation 2 yet, but he’s created models trained on both validation data sets. And as of the week before this Office Hours, Arbitrage finally installed XGBoost.

“I’ve got that spooled up, the models are uploaded to Compute, and I’m going to wait and see how they perform.”
Arbitrage said that he ultimately doesn’t think Validation 2 is relevant enough to be the sole focus of a single model, adding that if you have a model that performs well on both sets of validation data, or only has occasional misses on Validation 2, it’s probably a good model. He would be concerned if it performed well on Validation 2 but poorly with Validation 1, as that probably indicates the model is overfit to subsets of eras.
What’s a good correlation and sharpe for Validation 2?
We don’t know what good scores are for Validation 2 yet because it’s still too early, nobody has any results yet. “We’ll check back on it in a quarter,” Arbitrage said, adding, “some of us are training on it and some of us are not, I think that’s going to be an interesting bifurcation.”
He suggested that tournament participants should take note of which models are trained on Validation 2 and which are not (in Rocket.Chat for those who are willing to post), then shared that his models Arbitrage, Leverage, and Culebra Capital will include Validation 2 beginning with Round 210. Arbitrage 2, Leverage 2, and Culebra Capital 2 only train on the training data set.
Arbitrage: How about you, Michael Oliver? I’m calling you out.
Michael Oliver: I actually haven’t had time to play with Validation 2 very much. It’s on my to-do list: I want to run all of my models through it to see how they do. I don’t know if I’m going to change any of them in the short term. I’m really curious to see how my feature-neutralized models do, they seem to be doing okay so far with live data.
Arbitrage: Yeah, I can’t get that code to work. I have no idea what it’s doing.
Michael Oliver: What it’s doing? It’s basically doing a linear regression on the eras and then subtracting it off. That’s all it’s doing.
Arbitrage: So it’s performing a regression per era on the features, but if you neutralize your predictions in that first era, wouldn’t it depend on which era you pick as your first neutralization?
Michael Oliver: No, actually, because you do each era independently: for era 1, you do a linear regression from the features to the target, get a prediction of the target, and subtract that prediction off. Now your new target is neutralized with respect to the features in that era. Then you do that for every era.
Arbitrage: Ohhh, you’re doing it beforehand — I was looking at the code of the person who modified their predictions after the fact.
Michael Oliver: You could do that too, but I was training on neutralized targets. That’s how you neutralize the targets.
Arbitrage: See that I understood. When I saw the forum post, from I think Jacker Parker, they neutralized their predictions after the fact, and I didn’t quite understand how that was being done. But I think I’ll just stick with the target neutralization first.
Richard: Yeah, it’s really a projection. You’re trying to find out what’s the orthogonal component. You’ll have some of your signal strength coming from one feature, or a few features, and if you ask, “what’s the model saying if I’m neutral to those features?” or orthogonal to those features, that’s what the code we shared was about.
Arbitrage: Oh hey, thanks for that. I’ve been playing catch up on code since I finally fixed my XGBoost issues. I’ve been flying a little fast on getting all of this written down, so I haven’t really had time to sit and look at the code. Thanks for that, Michael, I did think it was a simple linear regression subtracting out.
Michael Oliver: I actually did both, and the method I talked about in Rocket.Chat a while back, too, where you one-hot encode all of the things then do the linear regression from the one-hot encoded values. Like a generalized additive model from all the features to the target. So I have one model that uses that type of neutralization and one that uses the linear neutralizations that they did as well. They seem to be performing a little differently. Doing it the second way that I called super neutralized doesn’t leave much signal left in there.
Arbitrage: Yeah, I would imagine. ‘Hey, let’s take a really hard data set and make it even harder!’
Michael Oliver: Yeah basically.
Arbitrage: Awesome. If you’re willing to post the code, I can put a notebook together and we can add it to the example scripts.
What are some recommended ways to use the feature categories?
Arbitrage explained that XGBoost has a way to designate which columns can be interacted, so he considered constraining XGBoost to only consider interactions across the feature groups rather than within them (because the features are thought to be correlated across time, e.g. Charisma from era 1 will still be correlated with Charisma from era 120).
He wondered what would happen if he restricted those interactions from happening within a feature group, and instead only looked at interactions across groups, such as Charisma interacting with Intellect.
Arbitrage added that neural nets and XGBoost, two of the traditionally best performing models, both look at interactions, so that might be a way to leverage the feature categories.
Elementary school-level question: why do float 16 (16 bit floating point numbers) or uint 8 (8 bit unsigned integers) data types in Python help reduce memory on trees but not on Keras?
“Good god I have no freaking clue.” — Arbitrage

Arbitrage admitted that he doesn’t have much experience in computer science (his background is finance), and so passed the question along to anyone who wanted to give it a try.
Keno: I just posted a link to a question on Stack Overflow: it’s basically because it returns a real number, so you have to convert it to a float. I had no idea, I had to look it up, but it makes sense that trees and XGBoost can give you floats instead of real numbers, whereas most neural networks give you a “yes or no,” binary output.
Arbitrage: Makes sense to me, I like it. I’d subscribe to your podcast.
JRB: I think I could probably explain this.
Arbitrage: Yeah JRB! Take it away.
JRB: With neural networks, and for that matter linear models, it’s usually a good idea to standardize your input. Essentially, the way you look at a tree-based model is that it tries to split the data set with the best possible split, so it's scale invariant. That being said, I don’t think there’s anything preventing you from training a neural net with quantized features (that’s what I do for my day job). I do a lot of model quantization, which is essentially trying to compress models to fit them on mobile phones and embedded devices- there it’s all quantized. It makes convergence a lot harder, but there are a lot of tricks. You can train a neural net with quantized features, but it’s easier with full precision features which are standardized with zero mean and unit variance.
Arbitrage: Thanks for that, that’s very helpful.
Michael Oliver: I think by default, Keras will just convert everything to float32, also, unless you do work to tell it not to do that. They usually want things to run on a GPU, which is usually float32, so by default Keras is just going to up-convert anything you pass it.
JRB: One thing you could do if you’re using Keras: there’s a layer called the lambda layer and you could possibly feed it quantized inputs and upscale the first layer in your batch to float32. I haven’t used Keras in a while, so I’m not sure if it will work but it’s definitely worth trying.
Arbitrage: Yeah, what neural network modules or packages are people using these days? Anybody willing to divulge?
JRB: I’ve been using Jax for a while now and it’s pretty good.
Arbitrage: How about you, Mike P? The Master Key model’s built in which framework?
Mike P: Master Key is built in a very simple framework called scikit-nn, it’s a basic Keras wrapper for scikit learn. It lets you play with all of your models like XGBoost just using simple, feet-forward monads, so it’s pretty crazy. It gives you access to things like dropout and all of the popular bells and whistles, but it doesn’t let you try crazy stuff like custom loss functions or anything like that.
Arbitrage: I don’t believe you, I don’t believe you at all. But, to each their own. I really appreciate all of the community members stepping up to answer questions I have no idea about or have no business answering in the first place. I don’t do neural nets, don’t profess to know anything about them at all: my knowledge of neural nets is very basic and I know there are some experts in this crowd.
I feel emboldened by the new machine I got. Does it make sense to make a massive neural net with hundreds of layers and tons of custom features, or am I wasting my time?
Fresh off of building a new computer (with input from Joakim) and with XGBoost finally installed, Arbitrage related to this question. He doesn’t think it makes sense to build a complex model, referring back to his conversation with Bor (who uses an intricate genetic algorithm) comparing their model performance.
“It goes back to Occam’s razor, which is going to be my default answer when it comes to choosing complexity over simplicity.”
Was Validation 1 not very representative of the old test set? Is Validation 2 more similar to the new test set? Do you think Validation 2 is more representative of live data?
Arbitrage thinks Validation 1 actually was a good representative set because he trained on it and maintained a ranking in the top twenty for two and a half months, saying it had to be representative otherwise he wouldn’t have performed nearly as well.
Regarding Validation 2, Numerai didn’t provide a new test set, they’ve used a subset of the test data to create an additional validation era. He urges caution in treating Validation 2 like live data, because the COVID-19 regime change is included in the Validation 2 set.
“It’s the combination of Validation 1 and 2 that matters,” he said, “because it’s more validation data than we’ve ever had before, and it’s disjoint in time and also regime. That’s an awesome validation set. I want to discourage the thinking of it in terms of ‘Validation 1 and 2’ and look at it instead as just ‘validation.’”
Joakim: I plan to use Validation 1 and 2, with 2 as my test set at the end when I’m done with my model. If it does hold up, I’m hoping that it will do well on live data as well.
Arbitrage: I think it will. If you can get consistency for the entire validation set, all, 20 eras? I can’t remember the whole count.
Mike P: 22.
Arbitrage: Thank you. If you do good across all 22 eras, you have a very good model. Previously, if you did well on all 12 validations eras, you had a pretty decent model. The additional eras add more validation. It makes your validation just a little bit better — as long as you don’t peek too often! You validate your model on the validation data, you’re done. That’s it. That was your hypothesis test. If you do it again, you have to divide your test statistic by two (if we were doing this in an empirical sense). Every time you take a peek at the validation data as an out of sample test, you’re reducing it’s validity as a test. That’s why I urge extreme caution with all this stuff.
Joakim: If it doesn’t hold up on Validation, what do I do?
Arbitrage: So let’s say if you get negative results across all eras?
Joakim: Just start over with something else?
Arbitrage: Yeah… sorry man.
Arbitrage: Check your cross-validation, make sure you’re not looking at all the data at once in every model run, last week I mentioned I tell my students to divide the data into three sets, train models on each one, then average them together and you’ll get better performance. If you do improve, it shows you were overfit and the ensembling of the models cancelled out some of the bias and produced a decent prediction (even though it’s still overfit).
What if I merge Validation 1 with the training data so I get more data to train on? I’m just a newbie to data science.
Arbitrage noted that this combination strategy is exactly what he does. He said you can combine eras 1–120 with 121–132 and use that as the training data. The challenge with this method is that you don’t have any data to use for validation, so you have to upload your predictions to the tournament then wait for your scores to post to see how well the model performed.
If you wanted to try this strategy, Arbitrage said the important things to remember are to make sure the parameters are set for each model, and do everything you possibly can to avoid overfitting.
Bor asks: Are there other indices out there (like the VIX) that track something interesting? Maybe a zero-beta fund or index?
As Arbitrage pointed out, finance people love building indices and portfolios to track different metrics or hypotheses. He said that there is actually a hedge fund index (such as the one from hedgefundresearch.com), and those indices have different categories of hedge funds.
There’s also an AI index and an equity/quant index. Richard added that a lot of funds that are doing well don’t report to any of the hedge fund indices, whereas the ones performing poorly do, so these indices may not be the best.
Arbitrage asked Richard if he’s aware of any indices that track flow of funds into different strategies for hedge funds, but he wasn’t aware of any.
How can I time the moment so I can change the stake of my model?
This refers back to the topic of risk management (discussed at length in the previous Office Hours).
“I decided I don’t want more than 400 NMR at stake on Arbitrage, so in the current regime I have to guess if I’m going to go over and time it one month out how much I should withdraw. The alternative is: if your model is consistently growing, queue up a withdrawal of a fixed amount every time that you can.”
To get more insight into what future staking and withdrawal systems will look like, Arbitrage turned it over to Jason or Mike P to chime in. Mike P noted that it’s still too early to discuss in great detail, but they are working on redesigning the staking mechanism based on feedback in Rocket.Chat, particularly because some rules changes that shift the tournament from a daily to a weekly mentality make previous methods obsolete.
Are there signals showing changes in the market conditions? #StakingStrategyisnotDead
Aribtrage: I completely agree that #StakingStrategyisnotDead but I just don’t know how we can utilize any information to improve our staking outcomes other than we should be able to adjust our stakes down as fast as we can increase them.
Marcos’ book talks about discrete maths and quantum computers: is there an introduction about these topics?
Author’s note: this question refers to Advances in Financial Machine Learning by Marcos Lopez de Prado, newly announced as Scientific Advisor to Numerai.
Outside the scope of his field, Arbitrage wasn’t sure what good content primers on these topics would be, but suggested asking in Rocket.Chat.
Arbitrage: And spiking neural nets? What’s with all the neural net questions this week? You guys are killing me. I don’t have a clue what a spiking neural net is and I don’t think I want to know. I’m going to punt on that too. I thought they were fake, but they are a real thing and it’s actually pretty interesting but I don’t have a clue if you could implement something like that and have it work.
Michael Oliver added that for the Numerai tournament, implementing a spiking neural net is probably more trouble than it’s worth. “Generally there’s no real advantage for spiking neural nets for most statistical machine learning problems,” Michael said. “Theorists find them interesting for modeling what brains actually do but if you’re just trying to learn a function, there are more straightforward ways.”

Arbitrage then added that if you have the ability to create a spiking neural net and can iterate it, it’s probably not a bad thing to try because it will most likely have high MMC (because nobody else is using that strategy).
Why are you not using staging for deploying changes to the user interface?
Arbitrage redirected the question to Mike, who immediately called for backup. His interpretation of the question is that person wants to know if users can have more input before big UI changes.
Mike P: My response to that would be probably a lot of it is turnover time … Patrick, I see you jumping on, thank god.
Patrick: We’ll test it in production. I think we can do more testing in staging. Multi-accounts are actually in production now, but they’re feature-flagged in a beta group. I think we can do more of this testing, it’s just a matter of us implementing it. It’s great feedback.
Unfortunately, I can’t participate (differences in time zones), but I want to listen to what you will discuss in Office Hours. Can you record and post a link to the video?
Each week's Office Hours are summarized and published in the Numerai Tournament Docs: see Season One and Season Two.
You can find the recordings on the Numerai YouTube channel.
Arbitrage also teased that over the summer, he’s looking forward to producing more content and playing around with how it’s shared with everyone.
Arbitrage asks Michael Oliver about his era-boosted trees: The only optimization parameter for the era-boosted trees is the correlation, is there a way to do era-boosted trees with two optimization parameters?
Enjoying his newly-installed XGBoost, Arbitrage was experimenting with the era-boosted tree code Michael Oliver posted on the Numerai forum.
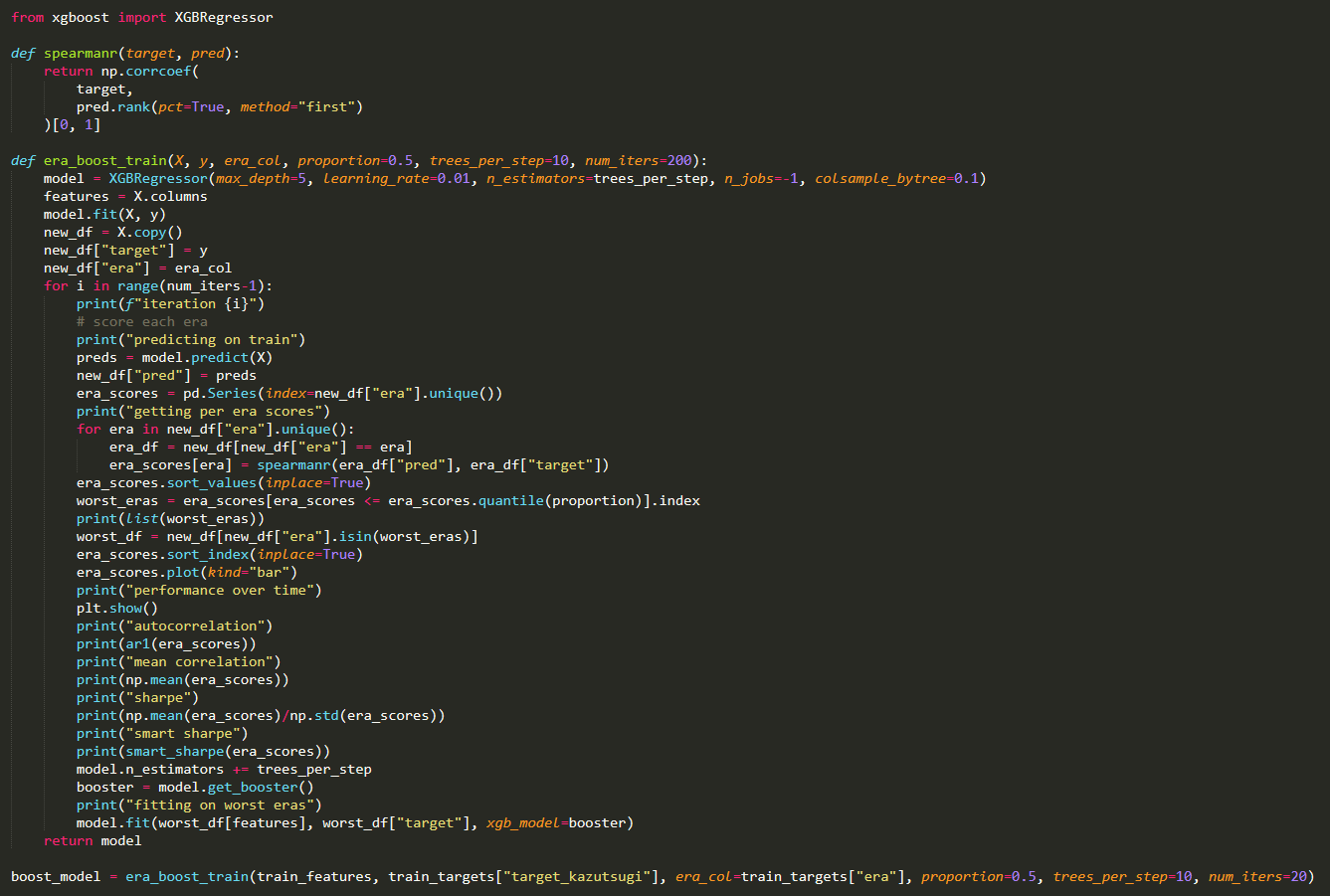
Arbitrage: I played around with the proportions, the number of trees — this thing is so grossly overfit I don’t know what to say.
Michael Oliver: I mean yeah, you can play with all of the parameters of XGBoost as well, too. You can change the column sampling, the proportions (as you said). You can add whatever metric you want. It’s just using a mean-squared era to fit the thing, and you’re choosing which eras based on whatever metric you want. You could potentially put an auto-correlation metric in there, too.
Arbitrage: That’s something I want to improve. I finally got it to a point where I have a correlation on validation using the era-boosted notebook I put up, I’m at 0.037, but I think it’s grossly overfit because I’m showing sharpe scores of five or eight, and correlation scores of 0.4 in some cases.
Michael Oliver: Yeah, that’s a tricky thing to evaluate. If you look at the Integration Test model, its in-sample performance is super high. This idea that your in-sample performance and your out-of-sample performance should be the same doesn’t really hold.
Arbitrage: Not in this data set.
Michael Oliver: There’s interesting reasons for that, but the only real way that matters for evaluating how overfit something is, is out-of-sample performance. Worrying too much about your in-sample performance being too high, I don’t think it’s worth it. All that matters is the generalization performance.
Arbitrage: One thing I tried to do: I took the era-boosted notebook and I put 100 trees per step and I did 20 iterations to get to the 2,000 estimator equivalent of Integration Test. I’m still tinkering with that, but I find it very interesting. My concern is that it’s over-sampling some eras far too often.
Michael Oliver: I noticed oscillations of groups of eras falling in and out. On the histogram, it would get flat and then jagged, flat then jagged.
Arbitrage: Mike’s nodding along in excited agreement here.
Mike P: The proportion parameter’s really important to tune down that oscillation. If you turn down the proportion parameter, you’ll get much less oscillation and more consistent growth. But, 0.5 is what we’ve found to be the best in our tests. If you don’t like that oscillation or don’t trust it, you can try to get that down to 0.2.
Arbitrage: What did you guys internally tinker with? Just so I don’t have to do it myself.
Mike P: Not too much — it was an idea that had been floating around for a while and we wanted to put something out there so I threw together some code and so it wouldn’t take too long to run, I only used like, 200 trees. I played with the proportions a little bit; I saw the oscillations as well and wanted it to be a little bit smoother. But it’s all still wide open, I don’t know what’s best, honestly.
Arbitrage: Yeah, I’m going to toy with it some more. But at least there’s a notebook out there that works. And Michael Oliver, if you’re still willing to share it, I’ll put up a notebook with the feature neutralization code.
As a special surprise, during closing remarks Michael Oliver announced that, one month from recording, he would be joining the Numerai team. 🎉
If you’re passionate about finance, machine learning, or data science and you’re not competing in the most challenging data science tournament in the world, what are you waiting for?
Don’t miss the next Office Hours with Arbitrage : follow Numerai on Twitter or join the discussion on Rocket.Chat for the next time and date.
Thank you to Richard, Mike P, Patrick,_ JRB, and Michael Oliver for fielding questions during this Office Hours, to Arbitrage for hosting.
Last updated