OHwA S01E04
March 26, 2020 / Interview with Richard @Numerai
The one where Arbitrage interviews Richard Craib Written by http://twitter.com/mandelliant__
In the previous office hours, Arbitrage introduced a new segment where he interviews a member of the Numerai community or team (Numerati). For Office Hours #4, Numerai founder Richard Craib joined Arbitrage in the hot seat.

As more people joined Office Hours, Arbitrage thanked Slyfox, NJ, and Richard ( “Mr. Numerai himself” as Arbitrage put it) for joining, and kicked off the call with some questions specifically for Richard.
Could you ask Richard to come on and talk about hedge funds in general? How is the industry doing?
Richard explained that hedge funds report on their performance at the month’s end- this office hours was recorded on March 26th, a few days away from officially reported data. However, Richard pointed out that there are some journalists who have reported on how hedge funds are doing and what’s happened to some of them midway through the month.
“It’s quite easy to be market neutral: you just have as many dollars long as you have short. But you might not be neutral to other kinds of risks.” — Richard Craib
He referred to the often discussed hedge fund deleveraging risk, a situation where hedge funds with 6x or 8x leverage reduce to 3x or 4x in light of current market performance. This is equivocal to eliminating half of a fund’s position if it reduces from 8x to 4x.
“They’re selling the good stocks that hedge funds like,” Richard said, “and buying the bad stocks hedge funds don’t like. When everyone does that on the same day, you can have very big swings. Some of the swings you’ve seen actually are probably connected with that.”
The more a hedge fund can be neutral towards, the better, and Richard explained that Numerai is neutral to a lot of factors. He used the example of exposure to both value and momentum funds, something many hedge funds have and neither of which met performance expectations in the month leading up to the Office Hours.
“The less you’re exposed to that, the less likely you are to be holding the same types of things other people are holding, and that’s definitely what we’re trying to do at Numerai: have a hedge fund product that does well when others do badly.”
Are we able to guestimate the fund’s alpha by stake value x MMC x delta, and if so, did we outperform the market these past two weeks?
This question came from Keno in the chat, and is something Arbitrage has considered. From his perspective, the data scientists have no idea how much leverage Numerai may or may not be using, which would bias the results. “Given an optimization problem,” Arbitrage explained, “it could be very difficult to extrapolate from how we’re doing into [how the fund is performing].”
Richard said that signal performance is very connected, explaining that most models have parts of the integration test model. He said Numerai uses leverage about 4x the fund’s gross, but given that, he doesn’t think someone could look at an average model’s performance, or the Integration Test model’s performance, and use that to gauge how well the fund is doing. “We’re putting those signals together,” Richard said, “and then doing this whole big optimization step where we neutralize to things you guys can’t see, like being country neutral or being neutral to a specific currency, and we have to take that out.”
“It’s hard to say, some days it looks correlated, but it’s not, really.”
Arbitrage pointed out that several data scientists have apologized on Twitter and RocketChat; Arbitrage himself admitted not long ago that he was wrong about how market volatility would impact model performance.
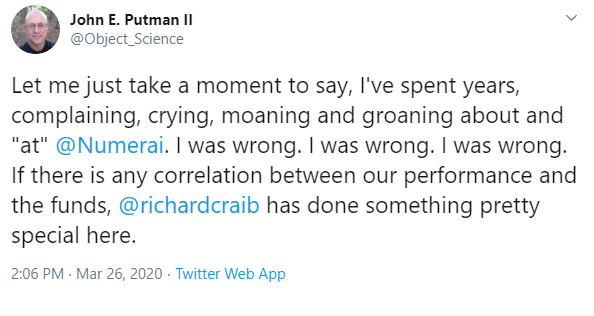
All that being said, the community still wants to know (as evidenced by how many upvotes the question received on Slido): is there a correlation between performance of the VIX (CBOE Volatility Index) and Numerai’s burn rate?
Richard explained that there was a significant market drawdown which began in February, and the VIX went up during that time, but in actuality it was the hedge fund deleveraging risk (occurring during a period of high VIX performance) that had a more noticeable impact on Numerai data scientist model performance.
“I think it’s a waste of time to think, ‘I’m going to put my stake up because the VIX is low and I think it will stay low.’ … Numerai is not a derivative of the VIX.” — Richard Craib
Arbitrage went on to note that, despite the large drops in the market, his recent models were performing better than he expected, crushing all of his prior models. For Richard, the fact that Arbitrage’s models were so drastically uncorrelated with market performance made perfect sense.
Richard explained that when Numerai provides backtest data to investors, that data can’t reflect any degree of correlation to something like the volatility index. He said, “If they come back and say, ‘this is 70% correlated with the VIX,’ we don’t get money from them. It has to be 0% correlated.” By design, Numerai has taken out these known factors to make it more difficult for anyone to find a correlation.
Data scientists therefore can’t tie correlation to the fund’s performance. Arbitrage asked Richard if it’s possible for individual models to end up correlated with some factor, which would then give the appearance of correlation.
“What is possible,” Richard said, “is for your own models to take on feature exposure.” Arbitrage discussed feature exposure in the first and second Office Hours, and Richard’s point about models taking on feature exposure reinforced what Arbitrage said specifically about how optimizing for features can lead to overfitting the data. Richard said they were looking into neutralizing to the features, suggesting that looking at correlation against the Validation data after neutralizing out all of the features is a better way to gauge how well a model will perform out of sample.
“It’s like saying, you do your own optimization and take out all of the feature exposure you can: if your exposure is .10, get that down, and if you get that down, you’re going to have a better model.” — Richard
Richard explained that models with very high feature exposures, like a model fully optimized on just one feature, could conceivably be recognized as correlating to something in the market. He said that some of the features have more of a value tilt than others, so if a model is trained exclusively on one of those features, he wouldn’t be surprised if that model experienced lower performance at a time when other value investments were down. “Most models aren’t that simple, so I doubt any models are easy to read that way,” he said.
Author’s note: Numerai has since released an updated version of Metamodel Contribution, MMC(2), which includes feature neutral targets.
Arbitrage brought up a discussion with Michael Oliver from the previous Office Hours which was inspired by an idea from Richard: given that the new data structure has groups of features, it’s possible for a model to be trained on only one feature group and that finding performance that way could drive MMC (meta-model contribution).
Arbitrage: Do you still think that’s the case? ‘Will you vouch for me’ is basically what I’m asking here.
Richard: Um, I wouldn’t do that …

With the caveat that he personally wouldn’t train a model exclusively on one feature group, Richard said that he would drop certain features and possibly even entire groups as part of the learning process while iterating his model.
Richard: “We train on a lot of trees: maybe the first hundred trees can be on all of the features, then your next hundred maybe you drop some of the features because you don’t want to be so exposed to them in subsequent iterations.”
Arbitrage: “I’ll still claim you supported what I said, you just added a nice little twist to it. Still going to claim it as a support instead of a refutation. So I do appreciate that.”
Richard said the fund’s benchmark is the risk-free rate because they’re hedged. But what if the risk-free rate is zero? Also, that implies leverage: how leveraged?
“If you’re trying to be market neutral, to have your benchmark be the market is really stupid.” — Richard Craib
“If you want to have a market neutral fund,” Richard explained, “you have a long-only position where no one is allowed to have any negative or predictions below .5. If the risk-free rate is zero, we make money if we make more than zero.”
Do you think that the infinite money printers all around the world will cause our models to get more or less correlated with the data? Brrrrrrrrrrrrrrrrr
With a laugh, Richard agreed that it was an interesting question and mused that the lesson from the financial crisis seemed to be that, “you can print money and get away with it because the inflation doesn’t come so you don’t pay the price.” He added that the negative effects were more likely felt by other countries, “It’s definitely good for stocks,” Richard said, adding that a small crash and subsequent rise would be better than a situation like the stagflation of the 1970’s.
Would Numerai expand to futures and forex?
Richard believed that eventually Numerai would expand into futures and forex, but was firm on equities being the asset class best suited for what Numerai is doing, calling them “the real game.” Because there are so many equities generating so many data points, equities are better suited for machine learning tasks, as opposed to the relatively small number of different currencies, for example.
Arbitrage asks: what programming language do you use, and why?
Richard: I’m not a good programmer, at all. I didn’t study computer science in college; I took one computer science class and then did a machine learning class afterwards. That class was taught in R, so I got into R from that, and my early work from 2013 uses R. More recently though I’ve been using Python because nobody else in the company uses R.
Arbitrage: A little birdy told me NJ is an R fanatic.
NJ: Richard made me learn R in 2015 using twotorials.com. He would go to work at this asset management company and would tell me that by the time he got home, I would have to have written some loop a million times. I couldn’t understand why my laptop kept crashing — it was a trick and I fell for it.“
Arbitrage asks: can you tell us your top three tips for the tournament?
Richard: I think focusing on sharpe is the one thing we try to encourage. If you try to focus on sharpe, you’ll see how dangerous it can be to be maximizing the mean. If you try to maximize your mean correlation, you can make a model that has the best possible mean but right in the middle has four terrible months out of the year. What you really want is to make a model that has performance in all months. That would be a higher sharpe model, even though the mean is lower.
You can say, ‘I don’t care, I want to maximize mean. I can wait out the burns.’ But you’re missing the point: the point of maximizing sharpe is also maximizing your likelihood of generalizing to new data. The live data might be dense with eras like the four months you decided not to get good at.
Throwing Numerai’s data into a machine learning algorithm that cares about maximizing the mean score but doesn’t care about eras (where sharpe forces you to care about eras), that’s a big mistake people make. We have some new things coming up that will help people see that more clearly.
Arbitrage asks: who is your favorite team member?
Richard: Team member??
Arbitrage: I’m just going down the list, I asked this question to everybody. No bias here, it’s the same list for everybody.
Richard: It’s very hard — they’re very good! We have a lot of good people right now, we’ve never had a better team. Michael, who joined recently, is very good, I’m very happy with him. Anson obviously got promoted to CTO, for very good reason. I really like the team as it is now.
Arbitrage: That’s a great answer and similar to what I’ve heard in the past: nobody will pick.
Arbitrage asks: how many beers did you have at ErasureCon?
Richard: None … I did have some of the cocktails from the concession booths. But I feel like that was after ErasureCon?
NJ: You weren’t drinking during, you just wanted Diet Cokes.
Arbitrage: There you go, she gave you cover. That’s good stuff.
Richard: That’s our VP of Communications right there!
From Stelian: would you consider decentralizing the process of using tournament predictions to build a portfolio?
After Arbitrage finished his list of questions, he opened the floor to attendees, presenting an opportunity to ask Richard questions directly. Stelian was the first to speak up, asking if Numerai would open up the portfolio management process.
This follows closely with something Richard has been planning to do. He explained that the Numerai data scientists are currently given a whole vector of probabilities, but there could be another column on the upload that has a one if you want the stock in your longs and a minus one if you want it as part of your shorts, essentially making a portfolio. If data scientists have to choose 1,000 stocks, 500 long and 500 short, they might not want to choose the top 500 and bottom 500, instead opting for a more risk-neutral mix, avoiding too much exposure to one feature.
Erasure Quant (since ported to Numerai Signals) is set up to do two things: signal generation and optimization. But if the optimization is all machine learning, “it feels like you better tell the machine learning model what is going to happen to its signal. Otherwise, it will learn things.”
Richard shared that the first thing Numerai is going to do about this is introduce a new version of the target (which doesn’t have a name yet). The new target is going to be a feature-neutralized Kazutsugi target. Currently, the features all have exposure to the target, so when data scientists are training models, they like to use the features because they have correlation with the target. But, as Richard explained, making a feature neutral target forces data scientists to see how good their signals are independent of the features Numerai provides.
“That’s one way of getting at the same problem, where we’re at least telling you that we’re going to feature neutralize you down the process for the optimizer and the meta-model, so we might as well tell you to learn to get good at feature neutral modeling.” He expressed that this will be a continuous, ongoing effort, adding that getting the data scientists “closer to the real problem has been the story of Numerai, and this will be the next phase of that. Maybe the final phase will be this portfolio management idea, but I’m not sure if we need it if the feature neutralizing works well.”
From Keno: where are we with payouts? Are you comfortable with how the payouts have transpired over the last two highly volatile weeks?
In the two week period leading up to this Office Hours, the market saw a period of significant volatility which saw staked users outside of the top 100 burning sometimes up to 50% of their stake.
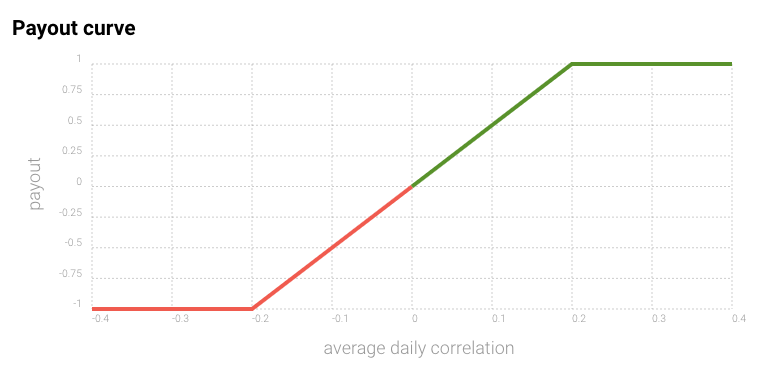
Payout is a function of a model’s total stake and it’s average daily correlation, meaning that for a 100 NMR stake, a daily correlation of -0.1 would result in a payout of -50%, burning 50 of the NMR at stake. Keno’s question reflects that correlation is likely to be far off during periods of high market volatility, potentially leading to significant losses for participants.
Arbitrage took the opportunity to plug #BurnInsurance (you can read more about his ideas from Office Hours #1 and Office Hours #2); Richard directed the question towards Michael, who has been working on improving the payouts system.
Michael mentioned that he’s been working on small changes to the payouts system to help reduce volatility (read his latest announcement for more details). The challenge, however, is that path dependency and automatic compounding cause data scientists to be more exposed than they would want during periods of high burn. “I’m still in the camp that if you want to burn less, you can stake less or build a less volatile model that’s less exposed to the bad periods.”
Keno countered with a good point, that because data scientists are working on a four-week time lag, they are unable to predict periods of higher volatility, noting that if he knew when the inflection point was coming, he would alter his stake accordingly. Specifically, the type of protection Keno is looking for is against unusual ‘black swan’ events, like a 10–20% change in the Dow Jones Industrial average.
Ultimately, as Michael said, Numerai can’t predict these kinds of events either, and they’re exposed just like the data scientists: “When you burn, we burn. It’s part of the game.”
Arbitrage, a long-time champion of #BurnInsurance, shared that even though he experienced significant burn, he’s up 10% from February 21st, putting him ahead throughout the volatile period. “Think of it in terms of a Darwinian experiment: only the strong survive. If you’re at the top of the leaderboard, you will survive the burn, and I think that’s an incentive to build a better model.”
Arbitrage reiterated his belief that if the data scientists can’t model it, they should be compensated for some of the unknown risk, but he noted that averaging across all of the weeks has helped significantly, resulting in him recovering from the volatility shortly after the market stabilized.
Richard added that it’s not because the Dow or the market dropped that users saw their models perform worse, “it’s just that the performance was bad.” He said it’s not the volatility that you can’t model, “that IS what you’re modeling — exactly that signal (whatever you’re seeing).”
The next point Richard brought up is the work the team has done around meta-model contribution. He pointed out how some users contribute to the meta-model week after week, regardless of where the Integration Test reputation line is going. “Once you can bet on that,” he said, “I think all of this volatility will go away.”
How MMC is formulated, from the meta-model contribution proposal:
We check how the stake-weighted metamodel performs with your model included (but we pretend you staked the mean, this way your mmc is independent of your stake size).
Then we hypothetically remove your model from the metamodel, and see how much it hurts/helps.
The difference in these two metamodels is your metamodel contribution.
We repeat this process 300 times using a random subsample of 67% of stakers each time.
The mean of a model’s score across these 300 trials is their metamodel contribution.
Richard brought up a post by a Numerai data scientist who shared his performance compared to the example predictions model- they were nearly perfectly matched up. Looking at that graph, Richard explained that most of the variance in that graph is explained not by what the data scientist is doing, but by the overall quality of the data. “Meta-model contribution means you can win no matter how good the data quality is, because you can always be better at modeling and contributing than other people and you can do that reliably.” This also addresses the volatility problem because with payouts based on MMC, models can perform well even throughout burn periods.
From Stelian: is it possible to condition the models upon submission such that they won’t output anything at a certain volatility threshold?
Stelian proposed the idea to set specific conditions when data scientists submit their models to act as virtual “insurance,” allowing the user to set some guard rails to protect against extreme volatility. He agreed with Richard’s statement that, “There’s no insurance in this business, it happens, everybody’s in the same boat and you can’t just buy insurance,” but pointed out that from a researcher’s perspective, it would be useful to have these conditions if you know that at a given time a model doesn’t perform well with high volatility. Following from that idea, Stelian asked if the features are provided in an obfuscated way to data scientists so they can make sure there’s no correlation when a model is created.
“The big trick there,” Richard said, “is that the target is neutral to these things. The Kazutsugi target is neutral to volatility: it’s exactly zero. If anybody says, ‘oh it’s volatility…’ it’s not.” Richard explained that because the Kazutsugi target is neutral to volatility, changes in the VIX, for example, would not be the sole cause of poor model performance. Instead, large swings in the VIX can affect other factors, which could impact a model (depending on how those features were incorporated during training). Learn more about Kazutsugi in Numerai in 2019
Learn more about Kazutsugi in Numerai in 2019
To emphasize his point about MMC, Richard pulled up a data scientist’s model which scored positive MMC nearly every week. He pointed out that despite the volatility of the market and the subsequent drop in performance of the Integration Test model, this model still managed to come out ahead in the majority of weeks. Model Niam from data scientist Michael Oliver.
Model Niam from data scientist Michael Oliver.
Michael Oliver was on the call, and was promptly asked, “what’s your secret?”
Michael O: Trying lots of things.
Arbitrage: This is the part of the show where we all talk about a lot of stuff but specifically nothing.
Author’s note: learn more about Michael’s approach to data science and the tournament in his interview from the previous Office Hours.
Is Stata useful or can it be used for the Numerai tournament?
Considering that Stata is primarily used as a research platform, Arbitrage didn’t think it could be used for the tournament. Though he noted the latest version allows for a Python integration, possibly making the platform useful for data processing or cleaning, Stata’s inability to use tree-based models ultimately discounts it from being useful for the tournament.
How well do your validation scores correspond to live scores? Any tips on getting the first to represent the second (besides no peeking during training)?
Arbitrage’s second favorite topic (behind #BurnInsurance) is validation scores.
“I look for a validation score between 3.8–4.4%” — Arbitrage
He’s found that if a model can get close to 4.4% without going over, generally speaking it will be a performant model, adding “your mileage may vary.”
Is grieving possible on millions of predictive signals to a level that is contributing effectively to the system?
Richard stepped in to answer this question: “Yeah, it’s possible now, and it will be possible with more [signals] as well.”
How many predictive signals has Numerai received vs how many does it use?
Richard: It’s between all of the stakers and half of the stakeless; it’s quite hard to beat the average of all of the users who are staking. The stakers do perform quite a lot better than people who aren’t staking, that’s for sure.
Does it make sense to use nonlinear dimensionality reduction methods in Numerai? If so, why and which are the most scalable?
Arbitrage said that he doesn’t do any dimensionality reduction in his model, nor does he tell his students to do so. Because it’s a clean data set, so Arbitrage is of the mindset that Numerai is giving the data scientists data that’s ready to go, so why would he want to do anything to it? “Especially when the signal is so low,” he said, “any transformation you make risks blowing up the signal.”
Michael O agreed, adding that one way to see what trees are doing is to expand dimensionality, which seems to work better than any nonlinear dimensionality reduction. He concluded that if anything, expanding dimensionality would work better before reducing it.
If you were to describe the learning process for a complete beginner to semi-competitive in the competition (including benchmarks), what would it look like?
As a finance PhD student, Arbitrage also teaches several courses including Financial Machine Learning with Python, where he uses Numerai data. Given that, he spends a significant amount of time thinking about this learning process.
Arbitrage: I’m going to assume you’re one of my students. You’re motivated to learn coding because you realized you can make a lot more money because you paid attention in my first lecture where I showed you salary differences between those who know Python and those who don’t. So you have some basic statistics and you’re motivated to learn.
You want to go from zero to hero in as short an amount of time as possible. You were smart, you enrolled at the university where I teach, and by fate you were getting your undergraduate degree while I’m getting my PhD, and you ended up in my class not because you chose me, but because you were forced into my class. By the grace of God I decide we’re going to do a coding project.
What I do is this: I give you working code and ask you to modify it in place. Quite simply, if I can teach you that this works, and here’s how it works, and if you change it you can get slightly different results. As long as I can teach you those concepts, we can move fairly quickly.
I’ve found that in four weeks, in about 12 hours of lectures and perhaps up to 20 hours per week of work at home (or as little as an hour per week, depending on how fast you grasp the concepts) — you can place in the top 150 on the leaderboard at the end of that 100-day trading period.
Arbitrage then pulled up a model from one of his students: Not bad at all.
Not bad at all.
The student, who had no prior coding experience, was ranked 119 at the time of the Office Hours.
“It’s definitely possible,” Arbitrage said, “but it takes a little hand holding. The key is to be dedicated to trying to break your model. I tell my students, ‘if you’re not getting error codes, you’re not trying hard enough.’ If you send me error codes, I can help fix that, but if everything works and a model does well, that’s just luck.” Referring to the student model he was sharing, Arbitrage said, “This isn’t luck. I helped him build his own model. He picked it, he designed it, and I made sure that his code executed correctly throughout time. And he’s going to pass one of my models soon. And I’m not happy about it.”
Arbitrage concluded with a resounding yes, beginners can absolutely learn how to compete in the Numerai tournament, with or without coding experience. All you need is about five weeks, a little guidance from someone with a high rank or who has been around for a while, and tenacity.
Slyfox opened that question up to everyone on the call, asking how other data scientists onboarded themselves into the tournament. Data scientist Bor shared his story:
Bor: I wanted to improve at machine learning if I wanted to be a scientist in the future, and I need a project to learn something and move forward. In the first years it was for coffee money only, but it was a nice start.
What’s a good validation sharpe?
Michael P answered this question, noting that validation sharpes are high values, with the Example Prediction model’s sharpe being around 1.5. Michael added the advice that the Example Prediction sharpe is “verification that you’re calculating things correctly, but you want to calculate your sharpe yourself on the cross validation and training set. You don’t want to rely on the validation sharpe to pick your model because the validation eras are too easy.”
Richard then brought up the Validation 2 data set Slyfox mentioned during Office Hours #2. Validation 2 is a data set the Numerai team are exploring which contains the previous year of live data, meant to be used as a more robust validation data set (or additional training data as Arbitrage and Bor pointed out).
 Excited for new data.
Excited for new data.
If you’re passionate about finance, machine learning, or data science and you’re not competing in the most challenging data science tournament in the world, what are you waiting for?
Don’t miss the next Office Hours with Arbitrage — you never know who might join. Follow Numerai on Twitter or join the discussion on Rocket.Chat for the next time and date.
Thank you to Richard Craib for joining this Office Hours call, to Arbitrage for hosting, and to Michael Oliver, Michael P, Keno, and Bor for contributing to the conversation. NJ, sorry you had to learn R.
Last updated